At work I do a lot of natural language processing and exploring large text datasets can be a bit of a challenge. One of my favorite ways to visualize text is by using word trees. Follow along to see an easy to create example of a word tree.
Word Trees
Word trees are graphs that allow you to start at a root word and follow the branches to see what words follow or precede the root word. This allows you to identify common phrases and all the little variations in sentences. As shown below you can see everything Biden said after tweeting “i want to”. You can also see how many times a phrase was used.

Code Provided
If you want to skip straight to the code go here https://github.com/cdurrans/word-tree-template. At the moment you’ll need python installed but I might make a executable program of this.
Once you clone the GitHub repository, you’ll need to run the following:
python "../repository/cloned/location/createWordTree.py" --templateFolder="../repository/cloned/location/template/" --data="../location/of/data.xlsx or csv" --column="Data Column Of Interest" --filters="Comma,seperated,list,of,filters,wanted." --saveDirectory="../folder/you/want/created"
Code Explanation
The code makes a copy of the template downloaded from my GitHub and then processes the data supplied.
It will read csv or xlsx files using pandas and then prepare the text columns for consumption by the JavaScript word tree code. The word tree code is generated using Google’s https://developers.google.com/chart code which currently has its word trees in development. So I expect to have to change the code on my template in the future.
What is Included
The current template includes the total number of text responses at the top left. Just below that is a text box for changing the root word, and in the middle is the chart. Below the word tree are the top trigrams in the text for inspiration so you can have ideas for things to look for. Above all of this at the top (not shown) you can switch between suffix, prefix, and double word tree options.
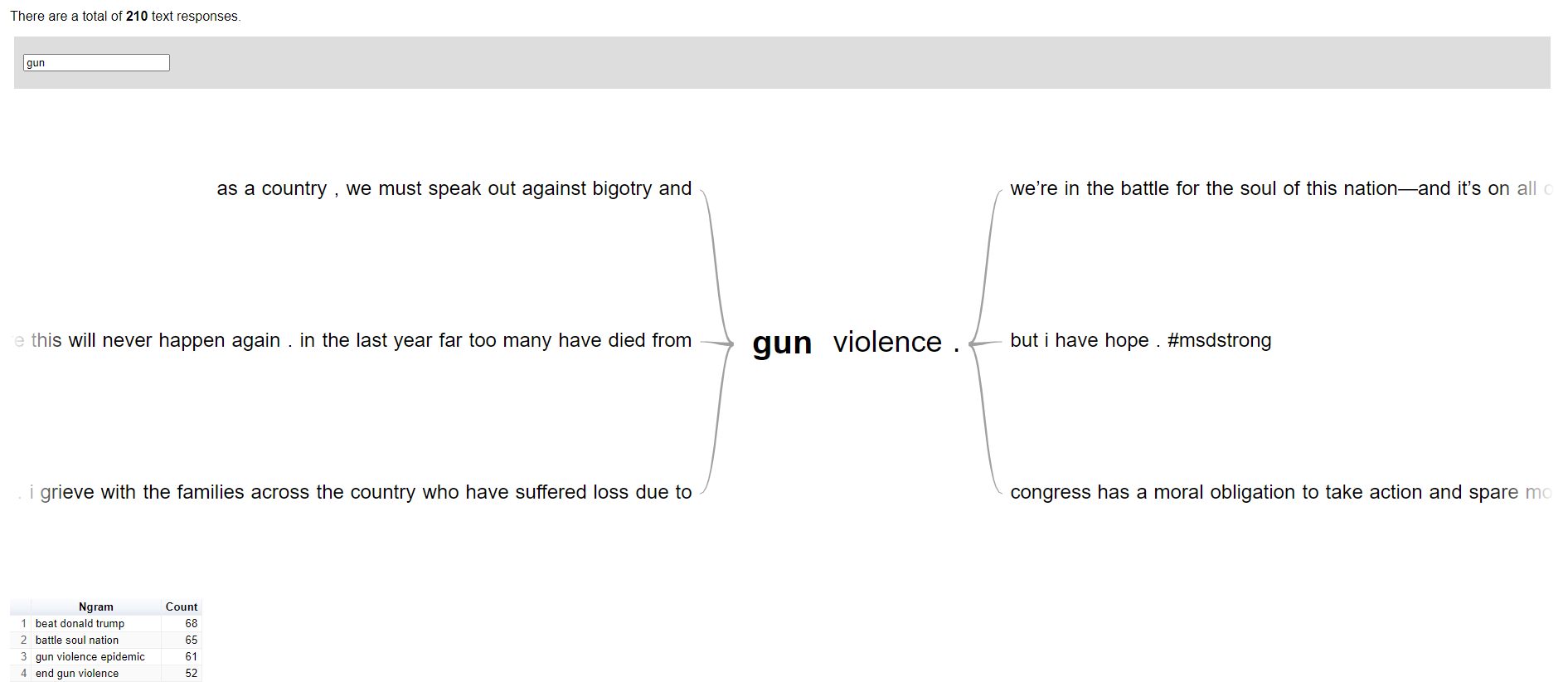
Data Set Used
While exploring what text datasets to use other than work ones, I decided to use Joe Biden Tweets from 2018 till late 2020. The data can be found here on Kaggle: https://www.kaggle.com/rohanrao/joe-biden-tweets
Limitations
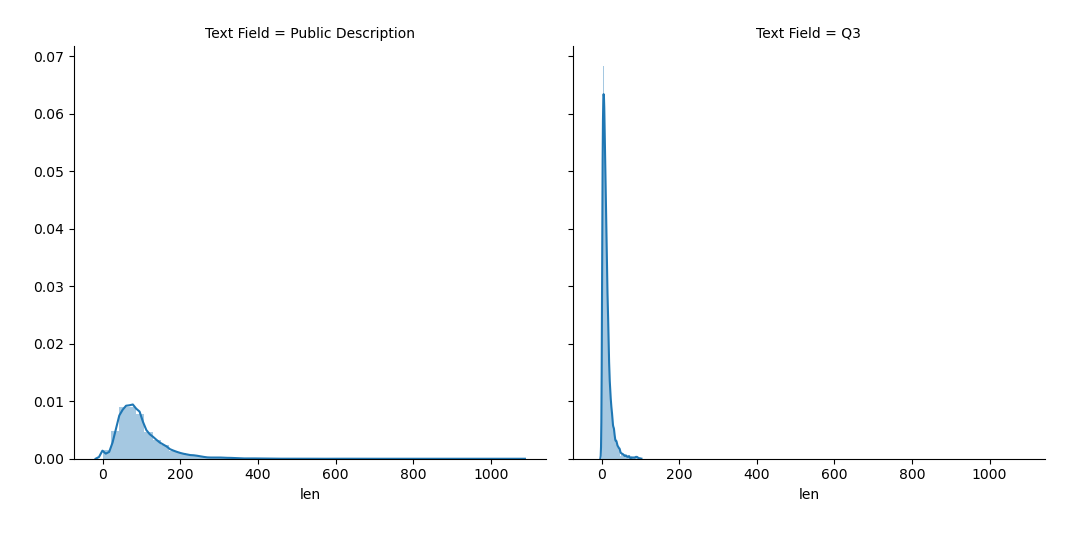
Google Chrome has a max of 4 gigabytes memory for each tab that is open. When working with lots of text samples you can easily reach this limit while using this visualization. This is because the JavaScript code will use more memory if the text samples are longer. While exploring some real estate home descriptions, I found that I had two datasets with comparable file sizes, but one had long texts while the other had a lot of short ones. The short answer word tree did just fine while the longer text dataset crashed the application with a max memory error. So, if you have long text responses consider breaking it up by sentence or consider taking a sample of your dataset. I hope google works on this issue with their code, because sometimes you can’t have very many text records, but considering I didn’t have to make it I shouldn’t complain too much.
Here is the distribution of sample lengths between the two datasets referenced above.
One other thing. I haven’t implemented different kinds of filters. At the moment if you supply a list of filter columns the date columns will cause it to fail. Also numeric columns will be treated as categorical so it won’t behave as you’d probably want. I plan to come back to this and fix it later.
Conclusion
I love word trees and I hope you find this template useful. I find it is handy for quickly getting a word tree up and going with little effort.