Using KDTrees and Euclidian Clustering with Lidar Points
KDTrees are a data structure that organizes data for fast retrieval using a similar idea to a binary tree and binary search. So before I explain kdtrees let me explain what binary search does. Binary search uses a sorted list of data and then splits the list in half and asks: is the value I’m looking for less than or greater than the median value in this list? If the answer was greater than the median, then it will split all of the points that are greater than the median in half and ask again. Repeating this pattern until the desired item is found. This really speeds up your search especially compared to a naive search that checks every number starting at the beginning of the list, because if you had a list of 100 items and the last item was the one you wanted it would check all 100 items before finding it, or in computer science notation O(n) time.
| Check Every Value | Binary Search |
|---|---|
 |
 |
This speeds up the search by quite a lot! Binary search takes Log2(n) steps to find an item in the worst case, so if you had a list of 500k numbers it would only take 19 steps in the worst case. KDTrees allow for improved search speeds as well, but instead of only being able to search a 1-dimensional list it works with items that have k dimensions.
KDTrees achieve this by first splitting the data into two parts, and then splitting it again based on another dimension rotating dimensions each time. So if you have 2 dimensions like x and y, it will split first by x then y, then x, then y and so forth. Let’s look at an example.
In the animation below you see it splits by the x median value and then on the left it splits by the y median and it continues.
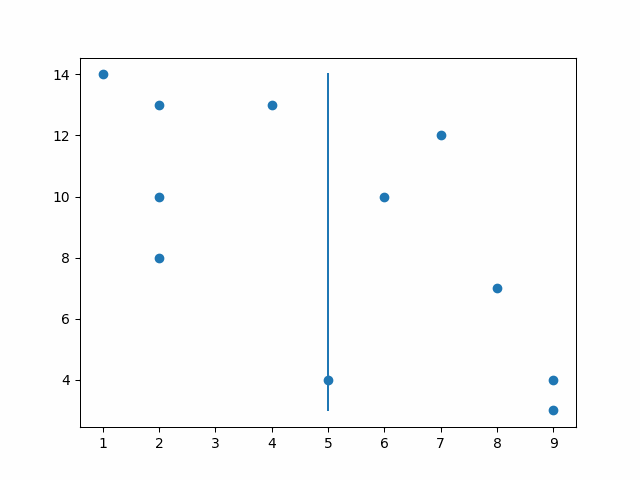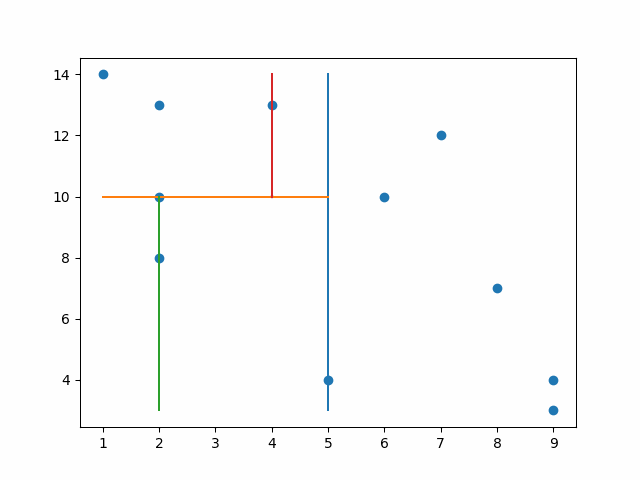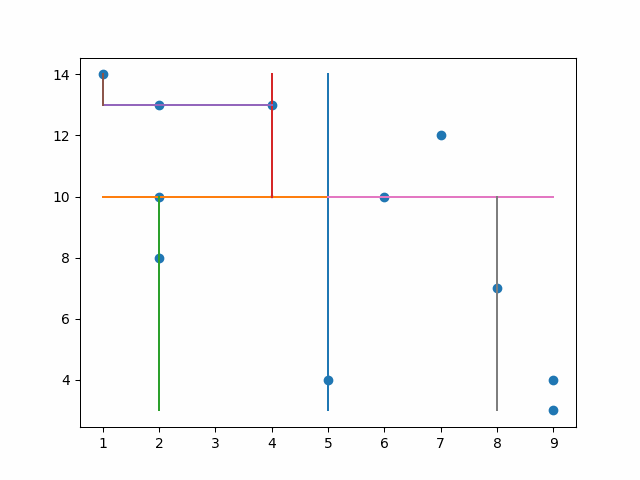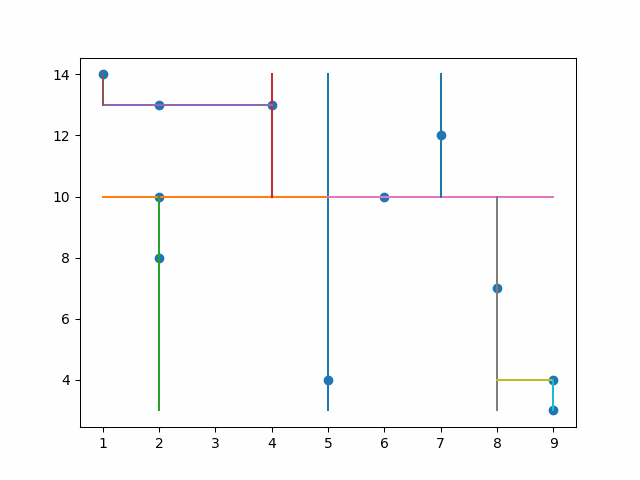
By splitting this way, the computer only has to search for values that are less than or greater than the first split and then the same for the following split and on and on. Later we will use this for Euclidian clustering with three dimensions, but first I want to note that it is important to have a balanced tree.
Balanced KDTrees
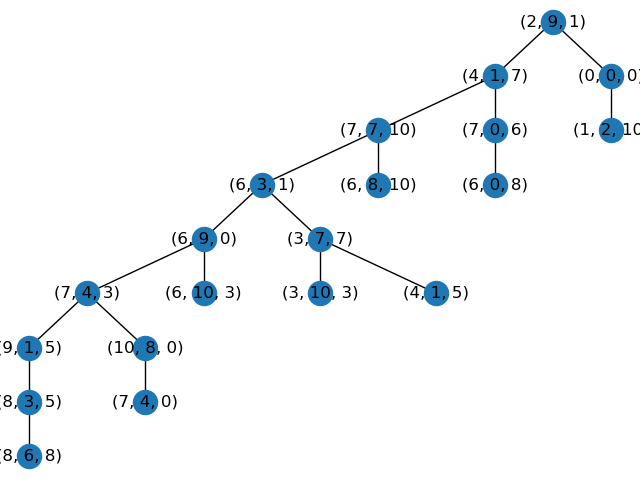
KDTrees are heavily influenced by the order in which nodes are added. If you have points added randomly you may have your first node’s value be at the extremely low end of the existing values which means almost every value would be inserted to the greater than side of the first node. We can fix this by inserting the median value of the first dimension which will create a balanced starting point. Then we can insert the median values of each of the following dimensions as we insert new points thereby creating a more balanced tree.
| Unbalanced Tree | More Balanced Tree |
|---|---|
 |
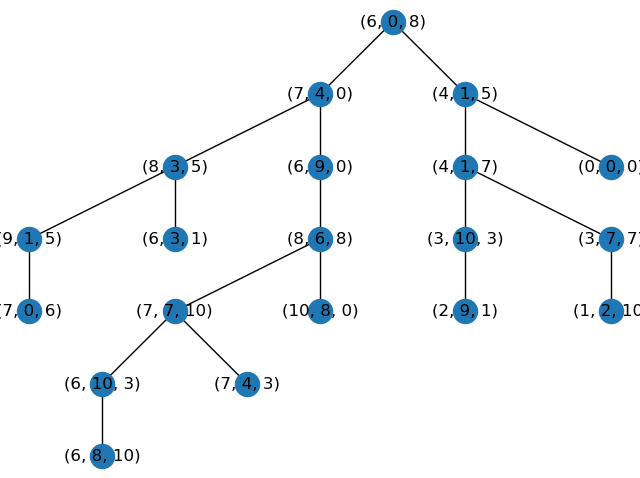 |
| 9 Steps to get to most bottom point out of 20 points. | 7 Steps to get to the most bottom point out of 20 |
Inserting points using the median values slows down the tree building time, but for a well-balanced tree the search time would be O(log(n)) for a tree holding n points. So it depends on your application and whether you care about building new trees frequently.
Euclidean Clustering
Now that we can build a KDTree what can we do with it? Well, we can find which points are nearest a new point. Below I have a 3d example of some sample points and the orange point is a new point located at (2,1,9) in this order (x,y,z), and I’ve highlighted points which are within the euclidean distance of 3.
For our eclidean clustering algorithmn it will do the following steps:
- 1. Build a KdTree with the data
- 2. For each point
- a. Check to see if point is in a cluster already, if so continue to next point
- b. Create a new cluster and add the point to it
- b. Add all nearby points (within a distance tolerance) to the new cluster
- c. Check the nearby points for other nearby points until there are none
Once this is finished, you’ll have to check to see if your distance tolerance is appropriate, but if it is you’ll have nice clusters. See the example below.
The nice thing about KDTrees and euclidean clustering is that it is fast enough to run on self driving car systems, so we can use it to identify other cars and obstacles on the road. In the image below you can see the ground segmented from the cars using RANSAC, and then you can see the cars as euclidean clusters with bounding boxes around them.
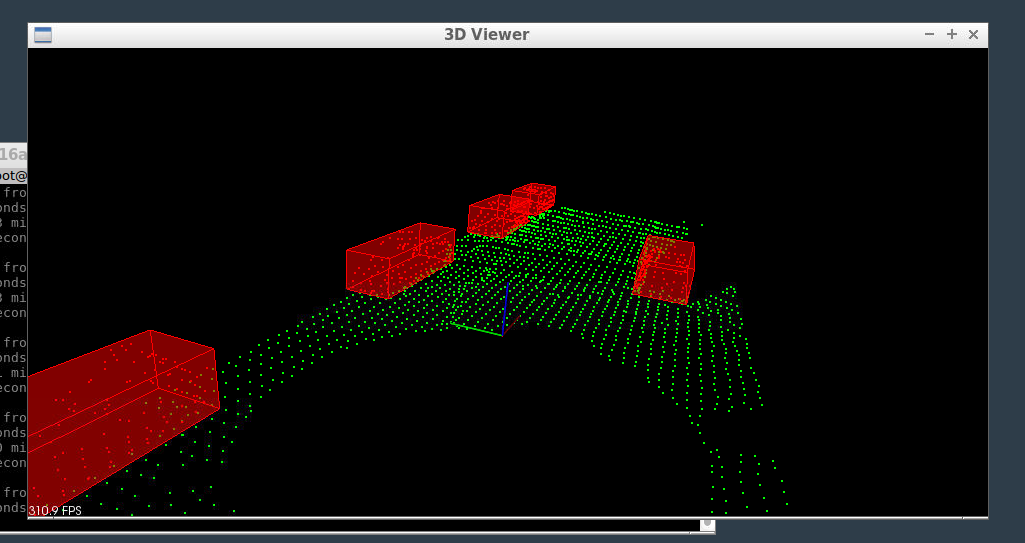
Thanks for reading and if you want to see the code I used for this blog post see here. If you want to see the C++ code using very similar code on real lidar data see here.
Cheers!